
我们写公众号文章会写一些热门相关的文章,也经常会遇到不知道要写点什么的情况,相信不少朋友都深有体会。这次分享我们用N8N工作流来解决写文章选题的问题。
通过结合强大的开源自动化工具 N8N + 飞书,我们可以解决选题焦虑的问题,让我们只需专注于内容创作本身。这套工作流可以自动收集并整理特定赛道的热点爆款文章数据,包括标题、链接、内容梗概、阅读量、点赞数和在看数等关键指标,并整齐地写入你的飞书表格中。
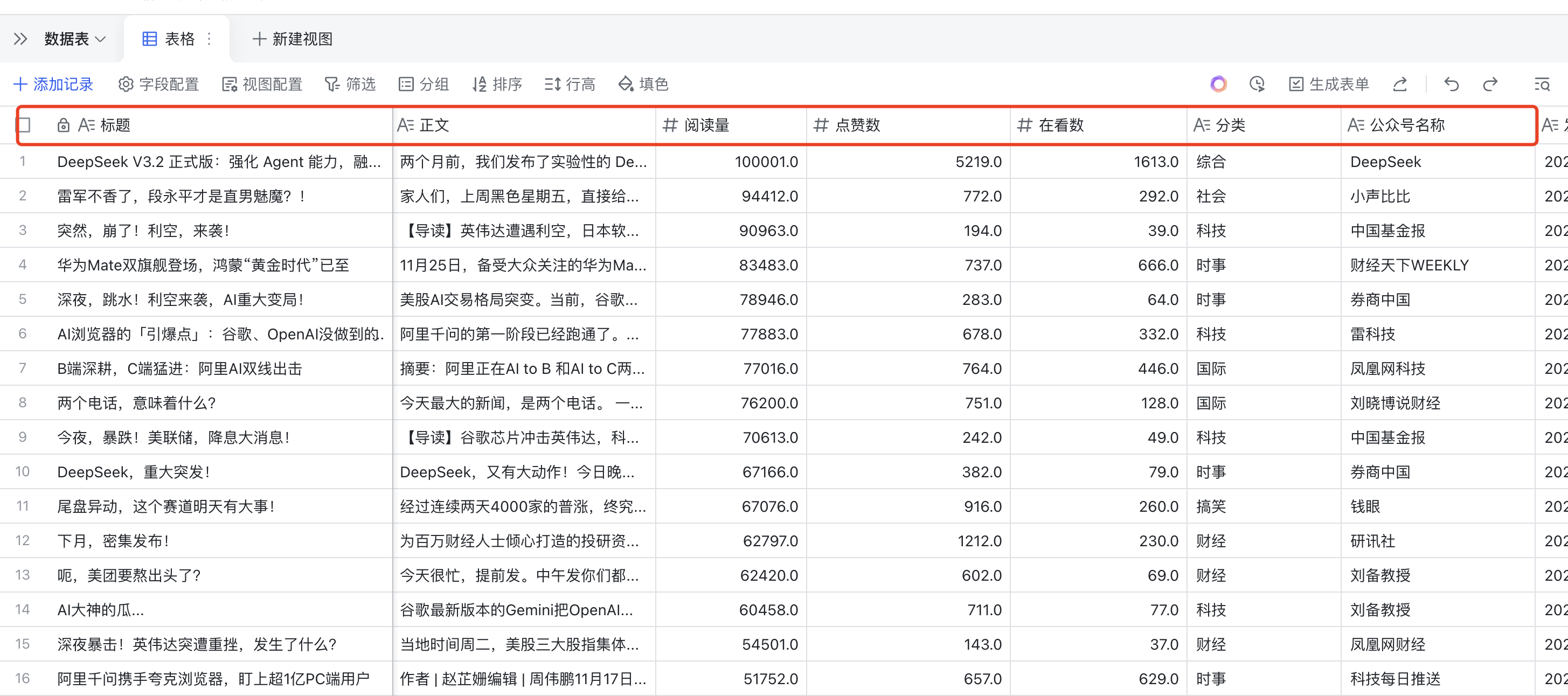
如上效果图,是我们自动获取到的最近7天的特定关键词的爆款热门文章。当然,我们也可以根据基于这些采集到的文章数据,我们在进行AI投喂和学习,并给出我们我们创造灵感、文章素材等。
为什么用N8N来采集热门爆款?
如果你写公众号或着博主,你是否曾为了“写什么”而耗费大量时间?
- 选题瓶颈:面对日益激烈的竞争,寻找独特且受欢迎的选题变得越来越困难。
- 效率低下:手动浏览、筛选、整理大量文章,不仅枯燥,而且效率极低。
- 灵感枯竭:长时间的重复劳动,容易导致创作灵感枯竭。
在数字时代,我们有更智能的方式来解决这些问题。借助 N8N 这样的开源自动化工具和 飞书 这样的高效协作平台,我们可以搭建一套自动化的内容灵感收集系统,将你从繁琐的“找选题”工作中解放出来,让你有更多精力投入到高质量内容的创作中。
自动化挖掘爆款内容
这套 N8N + 飞书自动化工作流 的核心目标是:通过关键词驱动,自动识别并收集你所在赛道的热门爆款文章,将其核心数据结构化展示,从而为你提供源源不断的创作灵感。
整个流程可以概括为以下几步:
- 输入关键词:定义你关注的内容领域。
- 自动检索:N8N 调用接口,根据关键词抓取近期热点爆款文章。
- 数据清洗:对抓取到的原始数据进行标准化处理。
- 结构化存储:将处理后的文章数据(标题、链接、阅读量、点赞数、在看数等)自动录入飞书多维表格。
- 灵感吸收:你只需要打开飞书表格,即可一目了然地分析爆款文章的特点,提取选题方向、标题技巧、内容素材,甚至可以进一步将这些数据喂给AI,进行更深层次的分析和提炼。
- AI自动给出(后续扩展):这一步会在后续我们来实现,会更加智能,直接给出我们需要的内容,如图里的虚线部分。
以下是整体工作流的简要示意:
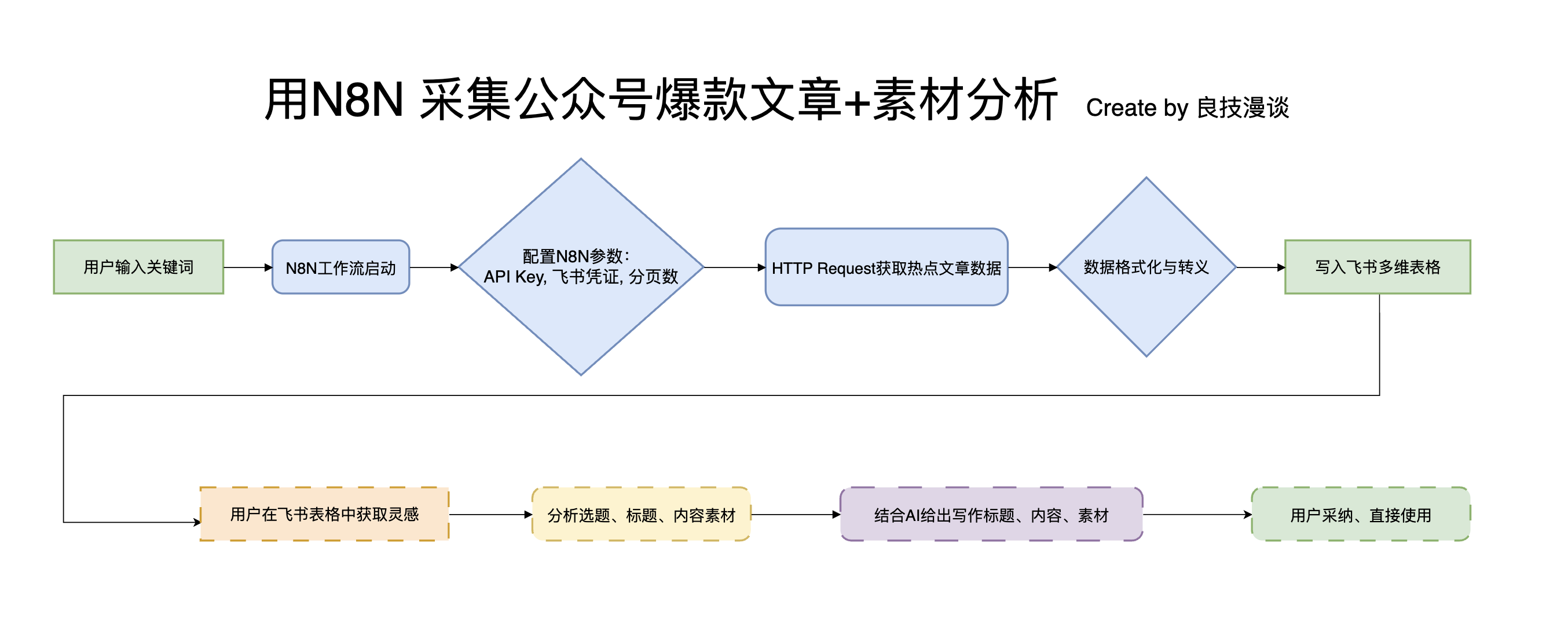
搭建智能采集爆款文章
现在,我们进入 N8N 工作流的搭建环节,我们先把需要搭建过程中的准备工作完成了。
准备工作
在开始N8N工作流的构建之前,我们需要做好一些基础准备。如果你是N8N的新用户,建议先完成本地部署并熟悉其基本操作。
安装飞书社区节点
N8N 的强大在于其丰富的社区节点。为了与飞书多维表格进行交互,我们需要安装
飞书社区节点。- 操作步骤:在 N8N 界面的左下角
设置 (Settings)中,找到社区节点 (Community Nodes),点击安装 (Install),然后搜索并安装 “Feishu” 或其对应的中文名称节点。
- 操作步骤:在 N8N 界面的左下角
准备接收数据的飞书多维表格
飞书多维表格将作为我们数据存储和展示的核心。
创建企业自建应用:登录飞书开放平台(个人飞书亦可),创建一个“企业自建应用”。根据提示填写应用名称、描述等信息(例如:“N8N公众号选题助手”)。
配置应用权限:这是关键一步。在新创建的应用中,前往“权限管理”页面,确保为应用授予 多维表格 相关的读写权限。具体包括:
读取多维表格中的全部数据、写入多维表格中的全部数据等。发布应用:完成权限配置后,务必将应用“发布”到线上版本。发布成功后,你将获得应用的
App ID和App Secret。这两个凭证是 N8N 连接飞书的“钥匙”。新建多维表格并绑定应用:
- 在你的飞书空间中新建一个多维表格。
- 进入该多维表格,点击右上角的“更多”->“添加文档应用”,搜索并选择你刚才创建的应用(例如:“N8N公众号选题助手”),完成绑定。
- 绑定后,你会在表格URL中找到其
Base Token和Table ID。请记录下这些信息。
设置表格字段(表头):为了确保数据能正确写入,请预先在多维表格中创建好对应的字段(表头),例如:
标题、文章链接、正文、发布时间、公众号名称、分类、阅读量、点赞数、在看数。
N8N 工作流构建
现在,我们进入 N8N 工作流的搭建环节。先来看一个整体的工作流预览,以便有个直观的感受:
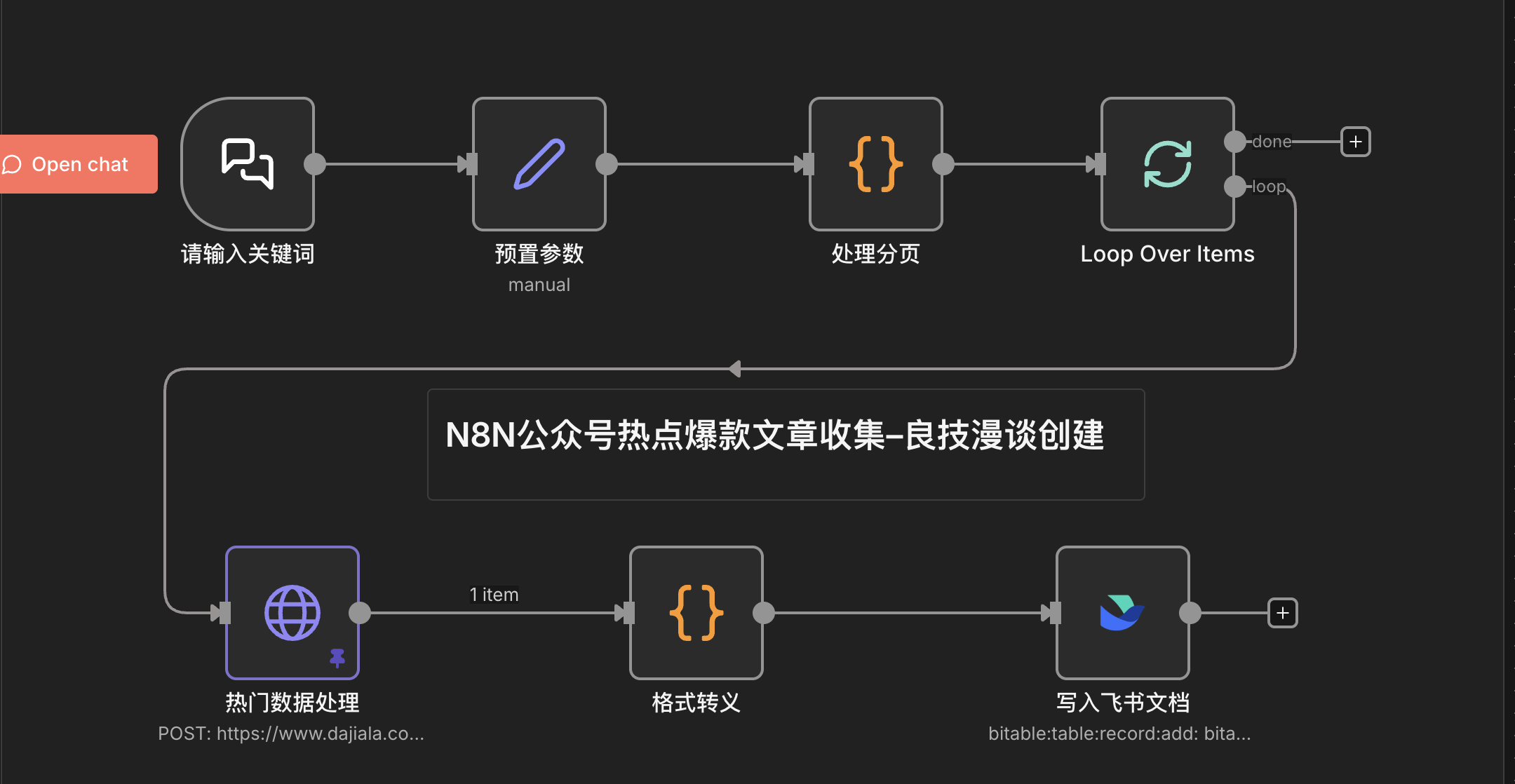
1. 关键词输入节点
工作流的起点是获取用户输入的关键词。这通常通过 Start 节点或 Execute Workflow Trigger 节点来实现。配置该节点,使其能接收用户输入的关键词,例如“gemini”或你所在赛道的任何特定主题词。
2. 全局变量预置
为了便于管理和后续扩展,我们会在一个节点中集中管理所有核心参数,包括飞书的凭证信息和获取热门文章的 API Key。
- 使用
Set节点(或类似的参数设置节点),将准备阶段获取的飞书Base Token、飞书Table ID,以及第三方数据接口的API Key、查询分页数量等信息定义为变量。 - API Key 提示:此
API Key是用于访问第三方热门文章数据接口的。通常这些接口提供免费试用额度,超出后需要付费。你可以根据自己的需求选择合适的第三方服务,或者自行开发爬虫替代。这个API Key将在后续的HTTP Request节点中使用。
3. 灵活分页处理
为了能够获取多页的热门文章数据,我们需要一个分页处理机制。
- 使用
Code节点,编写JavaScript代码来生成一个包含多页请求参数的数组。这能让工作流迭代执行多次数据请求。 - 示例代码:这个节点将为后续的
// 获取输入中的页数,例如在Set节点中定义 const totalPages = $input.first().json['页数']; // 生成分页数组:[{ page: 1 }, { page: 2 }, ...] const pages = Array.from({ length: totalPages }, (_, index) => { return { page: index + 1 }; }); // 返回结果 return pages;HTTP Request节点提供不同页码的请求。
4. HTTP Request 获取热门文章
这是工作流中获取核心数据(热门文章)的关键环节。
使用
HTTP Request节点,配置其向第三方数据接口发起POST请求。配置要点:
URL:第三方接口的地址,例如
/v3/kw_search。Method:
POST。Headers:根据接口要求添加
Content-Type: application/json等。Body:构建包含关键词、页码、
api_key等参数的 JSON 请求体。这个可以参考极致了的API接口。或者拿到我的这个json配置里进行直接用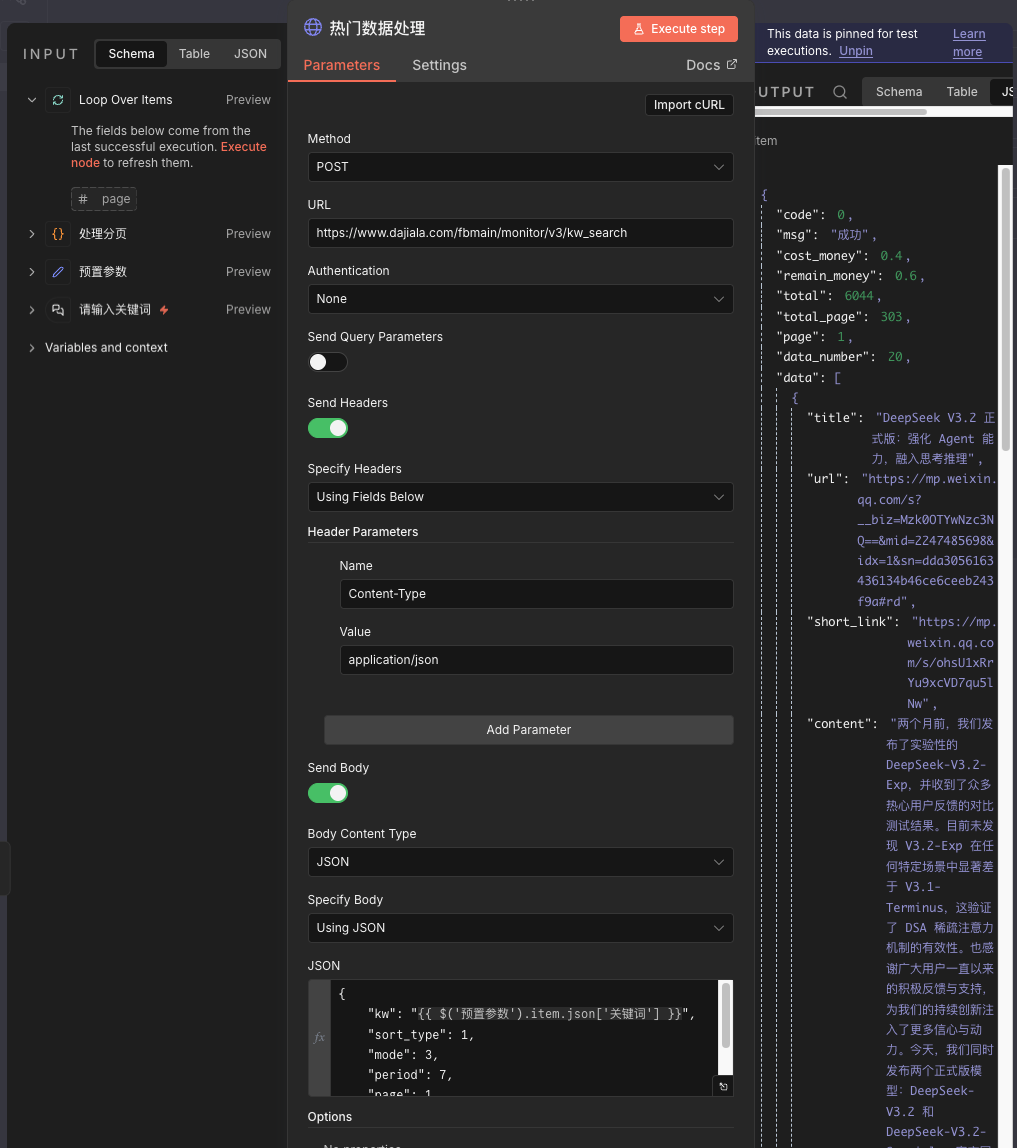
5. 数据清洗与格式化
从第三方接口获取的数据往往需要进行清洗和格式化,才能顺利写入飞书表格。特别要注意处理可能导致JSON解析问题的特殊字符。
- 使用
Code节点,编写JavaScript代码对HTTP Request返回的数据进行处理。 - 代码功能:
- 定义
escapeJSON函数,用于转义字符串中的反斜杠、双引号、换行符等,防止数据写入飞书时出错。 - 遍历接口返回的文章列表,提取所需字段。
- 将字段名称转换为飞书表格对应的中文表头(建议在实际生产环境中使用英文key,更健壮)。
- 对数字字段进行安全转换,确保不是数字时默认为0。
- 定义
- 示例代码:这个节点输出的数据将是一个JSON数组,每个元素都代表一篇文章,且字段名与飞书多维表格的表头一致。
/** * 转义 JSON 字符串中可能导致解析问题的字符 * @param {string} str - 输入字符串 */ function escapeJSON(str) { if (typeof str !== 'string') return str; return str .replace(/\\/g, '\\\\') // 转义反斜杠 .replace(/"/g, '\\"') // 转义双引号 .replace(/\n/g, '\\n') // 换行符 .replace(/\r/g, '\\r') // 回车符 .replace(/\t/g, '\\t'); // 制表符 } // 获取输入数据列表 const articles = $input.first().json.data || []; // 假设接口返回的数据在data字段下 const formattedData = []; // 遍历文章并格式化输出结构 for (const item of articles) { formattedData.push({ "标题": escapeJSON(item.title), "文章链接": escapeJSON(item.url), "正文": escapeJSON(item.content), "发布时间": escapeJSON(item.publish_time_str), "公众号名称": escapeJSON(item.wx_name), "分类": escapeJSON(item.classify), // 数字字段安全转换,不是数字时默认 0 "阅读量": Number(item.read) || 0, "点赞数": Number(item.praise) || 0, "在看数": Number(item.looking) || 0, }); } return formattedData;
6. 导入飞书表格
最后一步是将格式化后的数据写入飞书多维表格。
- 添加
Feishu节点,选择Create Record(增加记录) 操作。 - 配置要点:
- Credentials:使用之前在飞书开放平台获取的
App ID和App Secret创建飞书凭证。 - Base Token & Table ID:从之前的参数节点中引用。
- Records:将上一个
Code节点输出的格式化数据作为请求体 JSON。务必确保这里的 JSON 字段名与飞书多维表格的表头完全一致。
- Credentials:使用之前在飞书开放平台获取的
获得爆款文章
当所有节点配置完毕后,你可以在 N8N 的 Start 节点点击“执行”或“测试”,输入你关注的关键词(例如“人工智能”、“健康饮食”等)。稍等片刻,N8N 就会自动完成数据采集、处理和写入。
这时,你打开飞书多维表格,会惊喜地发现,所有热门爆款文章的关键数据已经整齐地呈现在你眼前,比如我们输入的是gemini这个关键词。
有了这些结构化的数据,你可以:
- 快速发现选题趋势:哪些主题近期热度高涨?
- 分析爆款标题:学习它们的修辞、关键词和吸引力。
- 借鉴内容结构:了解爆款文章是如何组织信息、引起共鸣的。
- 挖掘素材:直接从文章内容中获取灵感和论据。
- AI赋能:将表格数据导入AI工具(如 ChatGPT、Claude 等),让AI帮你进一步提炼核心观点、生成创意标题、甚至辅助撰写文章大纲。这无疑将你的内容创作效率提升到新的高度。
总结
通过这套 N8N + 飞书自动化工作流,我们不仅解决了公众号的选题焦虑,更重要的是,它为你提供了一个了解当下内容热点、分析爆款逻辑的强大工具。你不再需要手动大海捞针,而是能系统、高效地获取第一手内容创作灵感。
N8N 的潜力远不止于此。掌握了这种搭建思路,你可以将它灵活应用于日常工作中的各种流程自动化,无论是数据处理、信息同步还是重复性任务,N8N 都能帮助你大幅提升效率。
如果你对这套工作流的配置文件感兴趣,或者在搭建过程中遇到任何问题,欢迎在评论区留言交流。
获取这个N8N配置文件
可以关注我的公众号“良技漫谈”,回复“配置文件” 来获取 JSON 配置文件,直接导入自己的 N8N 环境中使用(记得改为自己的参数)
版权声明
本文作者:良技漫谈
本文链接:https://www.ljmt.online/blog/use-n8n-choose-topic/
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!


